

Большинство публикаций про статистику начинаются с известного выражения: «Существует три вида лжи: ложь, наглая ложь и статистика». Отличная традиция, давайте ее поддержим. Основания для скептического отношения есть, и для начала рассмотрим их.
Числовые данные выглядят веско, академично, убедительно — это же цифры! То есть элита среди фактов. А уж если было проведено исследование… Как можно спорить с выводами, которые сделаны на основании статистических данных?
Ну например вот так.
Манипуляции со статистикой
Прежде всего, надо проверять все эти «исследования». Что делать сложно, дорого, трудоемко, а зачастую и вовсе нереально. Вы же не будете покупать аналогичное уникальное оборудование, летать в прошлое, набирать полные больницы пациентов с определенными диагнозами, самостоятельно пересчитывать трафик на локациях и т.д.
Обычно мы принимаем все на веру. Никто кроме авторов исследований не знает, как на самом деле собирали исходные данные, какие из них попали в выборку, а что подчистили для красивой диаграммы.
Кроме того, ошибки бывают и случайно. Помните эпоху шпината? Когда не там поставили запятую в исследовании о содержании железа в зелени, все решили, что это чудо-трава, и стали пичкать ею детей. Прошло много лет, прежде чем удосужились проверить и снизить показатель в 10 раз. Но образ суперполезной зелени за шпинатом закрепился, похоже, навсегда – его до сих пор рекомендуют диетологи и врачи.
Ладно, пусть все цифры собраны добросовестно, никаких подчисток и опечаток нет. Теперь-то можно верить статистике? Как бы не так! Важно в каком виде ее покажут. Возможны такие манипуляции:
- Выборочный охват. Достаточно взять показатели за удачный период, и продукт демонстрирует рост продаж, а компания прибыльность. Хотя в целом ситуация может быть другой.
- Среднее вместо медианы. Если сложить оклады вахтеров и топ-менеджмента, получится бесполезная и ложная «общая картина».
- Игра со шкалами. Наводим мощную лупу на ось Y, и незначительная рябь по вертикали начинает казаться обвалом или взлетом. Часто применяется в курсах валют, ценных бумаг и акций.
- Относительные значения. Без инфографики тоже можно: вдвое выросло, втрое снизилось. Звучит громко, а реальные изменения могут быть незаметными. Например, было 2 – стало 4 (при общих объемах в сотни или тысячи).
- Нерелевантные метрики. Охваты вместо лидов, лиды вместо конверсий, конверсии вместо продаж — по одной и той же аналитике интернет-магазина можно построить множество разных отчетов. Одни из них рапортуют о победе над рынком, другие фиксируют провал рентабельности и убытки.
- Экстраполяция. Это мое любимое, тут лучше показать на картинке:
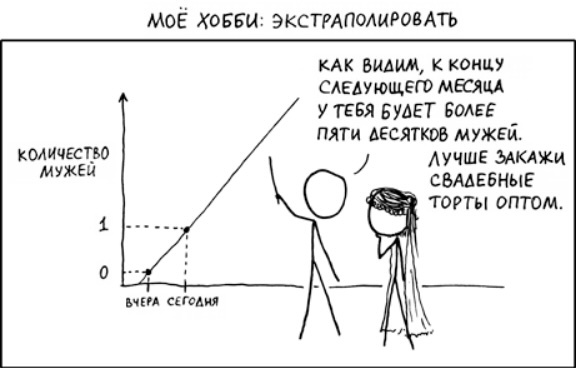
Ничего страшного, что ноль выше пересечения осей, так даже лучше. Классика жонглирования цифрами как раз в том и заключается, чтобы выстроить их под определенные выводы.
Наконец, и тоже в любимчиках – перлы с сайта Spurious Correlations. Там берут статистические данные с открытых источников и сопоставляют их для выявления корреляций. Выглядят они, например, так:
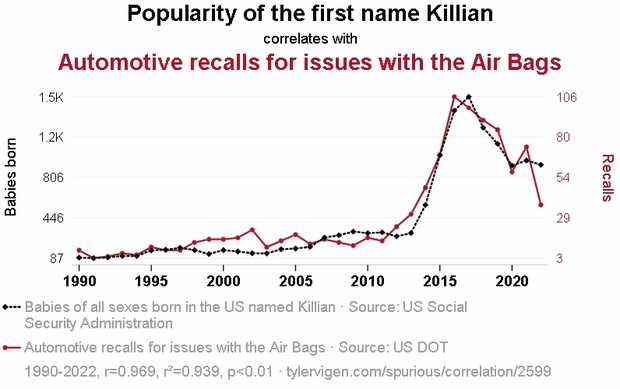
На графике выше наглядно показана убедительная связь между популярностью имени Киллиан и возвратами автомобилей из-за проблем с подушками безопасности.
Там полно чудесных корреляций. Среди них:
- Текущее расстояние от Сатурна до Солнца — количество поисков в Google по запросу «Как сделать ребенка».
- Популярность имени Маргарита — кражи машин в Индиане.
- Запрос в Google «Тейлор Свифт» — использование топлива на Вирджинских островах.
- Объемы ГМО при выращивании кукурузы в Канзасе — количество почтальонов в том же Канзасе.
- Популярность мема про парня, который оглянулся на чужую девушку — объем энергии, генерируемой гидроэлектростанциями Туркменистана.
- Потребление маргарина — количество разводов.
- Количество судей в Индиане — просмотры сериала «Теория большого взрыва».
Все эти корреляции настоящие. Они видны по реальным статистическим данным, на основании масштабных официальных исследований. Каждая находка снабжена графиками за много лет наблюдений.
Однако в том и проблема, что даже настоящие и полные цифры сами по себе никакой особой ценности не представляют. Все решает интерпретация.
Когда мы пользуемся чужой статистикой, она редко предоставляется бескорыстно и объективно. Обычно кто-то хорошо вложился в эти цифры, пытается чего-то лоббировать или продать с их помощью. Примерно как врачи в белых халатах на экранах телевизоров, пока их не запретили, наконец, в законе о рекламе.
А закона о статистике пока нет. Поэтому каждый использует ее как хочет. Одни данные утаивает, другие фальсифицирует, третьи показывает тенденциозно. И обязательно сопровождает выводами.
Готовые выводы, да еще на основании цифр — это удобно, конечно. Но спасибо, лучше не надо. Мы как-нибудь сами.
Как пользоваться статистикой
Действительно, лучшие цифры как подарок: должны быть собраны собственными руками.
С легким допущением к ним можно отнести и цифры, собираемые при помощи вендоров. Например, web-статистика по нашим собственным сайтам, строго говоря, не всегда такая уж «личная». Сохраняется риск ошибок на стороне счетчиков.
Не потому что Яндекс или Google коварно обманут с числом посещений, действиями пользователей на сайте. Бывают задвоения при неправильной настройке, можно случайно потерять полезный трафик из-за собственных фильтров, легко промахнуться с таргетингом, потерять часть данных из-за блокировок cookie.
К сожалению, даже полностью «свои» данные при ближайшем рассмотрении не совсем таковы, их сложно контролировать досконально.
Тем не менее все собственные наблюдения – однозначно, лучшие. Золотой фонд статистики можно дополнять сведениями от партнеров, отраслевым нормированием и далее по нисходящей, со все большими рисками и сомнениями.
Но даже такие цифры полезны. Их можно использовать по-разному:
- простым поиском составить первичный список конкурентов,
- оценить их расположение по онлайн-картам,
- прикинуть численность населения по данным 2ГИС,
- полистать публикации о сезонных колебаниях спроса,
- добавить еще пару метрик по вкусу — и бизнес-план почти готов.
Конечно, хочется брать цифры в основу любых рассуждений, планов и решений. По большому счету вопрос стоит не так: стоит ли использовать чужую статистику. Речь исключительно о степени доверия к ней.
И вот здесь начинается самое интересное. Оценка достоверности числовых данных — задача гораздо более сложная, чем их получение.
Как оценить достоверность данных
Есть формальные и относительно простые приемы. Сначала стоит провести отсев явных фейков, всевозможной числовой ерунды. Проще всего это делать по авторитетности источников. Условно, данные с РБК – хорошо, пост от юзера Вася200208 в соцсети – плохо.
Далее, смотрим актуальность. Исторические данные даже для выявления трендов сейчас подходят разве что с натяжкой. Какая разница, что там за динамика была до ковида и последующих событий. Фраза «Там уже их нет» из «Служебного романа» описывает не только ситуацию с гусями в СССР, но и много нынешних остатков по куда более широкому ассортименту.
Поэтому статистика нужна по возможности свежая. Дата публикации не всегда говорит о том, когда собирались данные. Тут уже надо покопаться.
Не помешает проверить хотя бы в нескольких разных источниках, лучше больше. Вдруг где-то ошиблись, показали только часть, мало ли еще бывает «нестыковок».
Солидные исследования всегда показывают методологию. Там должны быть все подходы, способы сбора информации, допущения, формулы. Как говорится, не приглашайте меня на вечеринку, если она не похожа по прозрачности на «Рейтинги Рунета». Но и они сталкивались с накрутками и подтасовками. Некоторые участники специально завышали количество сертификатов, вымогали отзывы с клиентов — все ради более высоких строчек.
Проверять «этичность» данных – от лукавого. А вот подумать об аффилированности участников процесса, пожалуй, стоит. Здесь придется выключить калькулятор, активировать гуманитарное полушарие мозга и задаться вопросом «Кому это выгодно?».
Сам факт публикации определенной статистики иногда может навести на мысли о том, кто за этим стоит и что вообще происходит. Особенно если речь не о регулярных публичных сведениях, а произошел внезапный «слив».
Кстати о них. Одно дело игнорировать чужую мораль, и немного другое — поступиться собственной. Большое число данных доступно, как бы это помягче, в серой зоне. Через хакерские базы данных, справочные боты в Telegram и прочие мутные схемы. Как ни печально, там довольно много настоящей информации. Актуальной, хорошо структурированной, достоверной. С учетом активности жуликов еще и полной. Флеш-рояль по ключевым характеристикам! Пользоваться ли этим великолепием и как именно – каждый решает сам.
Мой общий вывод по статистике: она похожа на Интернет. Очень много всего, по большей части условно бесплатно или дешево. При этом качество данных оставляет желать лучшего, проверять их бывает очень сложно и трудоемко. В конечном счете, только вы сами решаете, чему верить или нет, какие цифры отобрать для анализа и своих выводов.
P. S.
У этой темы есть еще один ракурс, возможно, самый важный. Будущее не предопределено. Там, где одни получили выдающиеся результаты, вас может ждать провал. На том же самом рынке, с похожим продуктом для тех же сегментов целевой аудитории. По цифрам все сходится, а по факту – нет.
Обратное тоже верно: если статистика выглядит удручающе, вы все еще можете преуспеть. Все шансы были против, а ребенок вырос чемпионом. Кукушка поленилась с диагнозом, а он прожил до ста лет.
Мы можем пользоваться историей в числовом выражении, но свою собственную историю пишем сами.
Будьте приятным исключением из любой статистики. Михаил Жванецкий однажды сказал: «Я так рад, что своею жизнью подтверждаю чью-то теорию». Представьте, насколько приятнее послужить ее опровержением.
Читайте также:





































Всем, кто сомневается в том, что Станислав в определенной мере прав, советую почитать книгу Фила Розенцвейга Эффект ореола, где он описываает, как делались статистические данные в книге "От хорошего к Великому", которую тут недавно очень рекомендовали в статье о 25 "умных и полезных книжках" ) Очень впечатляет )
Жаль, что это не закон.
Жаль что все кто что-то пришет на тему Парето -- не понимают, что эти 20% являются следствием тех 80% и неразрывно связаны с ними причинно-следственными связями.
Это все равно как рассуждать типа такого:
Полжизни человек проводит во сне. Это бесполезная трата времени.
Если у вас есть магазин в котором вы продаете 100 товарных позиций, то условно 20% будут делать 80% продаж. Казалось бы -- разумно избавиться от 80% и бизнес просто заколосится. Ан нет -- если вы так поступите, то из того что оставите примерно те же 20% будут приносить 80% продаж, а остальное -- лежать балластом. Продажи само собой рухнут а разы.
Начав работу в продажах, лет 20 назад и развивая бизнес в канале с дистрибуторами я обратил внимание, что даже зная что та или иная товарная позиция будет востребована слабо -- некоторые все равно включали ее в заказ. В небольшом количестве, чтобы было. И как они выражались -- для ассортимента, чтобы на полке стояло. Как ни странно, но это помогает ещё лучше проваться высоколиквидным позициям.
Это известная тема, но она не о статистике. Как и книга (2007), которая хороша как список известных автору заблуждений и ошибок. Хотя с момента её выхода было сделано много новых.
Немного о книге и интервью с её автором. С одним из тезисов я полностью согласен:
Я хочу помочь людям мыслить более критично. Чтобы они спрашивали себя: «Минуточку, а эти данные правильные или нет? Выводы верные или нет?». В мире бизнеса не все в порядке с мышлением.
Это закономерность, при этом 20/80 это общепринятая величина. Исследователи обнаружили и 1/7!:)
В некоторых функциональных зависимостях, взятых более узко можно обнаружить и что 5% деятельности приносят 40% результатов, а оставшиеся 15% приносят тоже 40%.
Главное даже не как и куда смотреть, а кто и как сможет воспользоваться. Статистическое упрааление результативностью - это искусство менеджмента.
У кого таких навыков нет, то соглашусь что возможна пустая трата времени.
У кого навыки есть, то пустые траты времени снижаются. Так глядишь и кадровые проблемы решить можно!:)
Согласен, хотя далеко не всегда можно понять, связаны ли эти 20% только с 80%, или такие результаты получены по какой-то другой внешней причине.
Вспомним, кем был Парето, и что он исследовал.
Она вообще не является фиксированной, а плавающей в зависимости от объекта исследования.
Распределение Парето -- это частный случай ранговых распределений. А пропорция 20/80 вообще ни разу не константа. Это просто канонический мем.
Когда вы только стартапите торговый бизнес и наполняете свою ассортиментную матрицу товаром, то можете словить и 5/95, когда 95% ваших продаж будут делать всего 5% товарной мартицы.
В идеале нужно прийти к 50/50 -- но на практике такое не достижимо. Просто в силу того, что на часть ассортимента вам потребуется снизить цену настолько, что они станут нерентабельны (ну или увеличить непрямые расходы в продвижение этого висяка, что в сущности то же). Поэтому для нормализации продаж всей товарной матрицы используют иные рычаги управления, а не простое выведение низколиквидных позиций из матрицы.
А куда подевался Месье Курочкин? Я волнуюсь.
И о статистике тоже ) Да, мне нравится мысль. кот. вы процитировали, но меня еще так папа учил ) Я читтала это интервью. Мне там нравится еще одна мысль )
–Но повторить их результаты не получится — рецепта у меня нет. Знаете, один человек прочитал мою книгу и спросил: «Где формула?» Я ответил: «Если ты ее все еще ищешь, прочитай-ка книгу второй раз».
Статистика выступлений А.Курочкина вызывает некоторую тревогу - резкое падение! И правда, что случилось? Надеюсь - хороший отпуск с выездом к теплому морю, где не до суеты сует.
Неожиданно. Как же так! Где советы автору заняться собой, окончить среднюю школу, научиться выращивать картошку? Прям не узнаю Вас )